
As mentioned before, I’m not a fan of using advanced analytic techniques for the sake of intellectual pursuits.
I’m a HUGE fan of asking good questions, framing analysis well, knowing data well, quickly arriving at actionable insights.
A trained data scientist’s toolbox has many statistical techniques, each of which has strengths and weaknesses. A health analytics professional should choose the method/s that best fits a specific analysis.
Over the past decade, I have found Decision Trees to be one of the most useful statistical techniques in my work.
What do Decision Tree algorithms do?
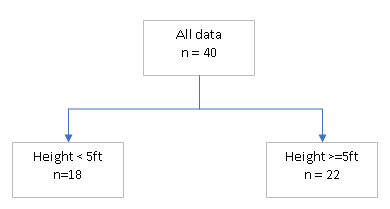
Very simply put, decision tree algorithms use the feature vectors (data labels) to split the dataset you have along one target variable (output measure). It will do so starting with the feature that creates the biggest difference among the resulting branches. It will then go down each branch and further splits the data points in that branch.
For example, we have a dataset of 40 patients with feature vectors containing weight, height, prior diseases, and a target variable of whether a patient has backpain. In the example, the initial split was less than or greater than or equal to 5ft of height. The algorithm will further split each side of 5ft using other feature vectors.
Simple to set up
Decision trees are relatively easy to set up and execute as they do not require a lot of user input.
You can specify whether you want 2 or more splits at each branch. And you can also specify how the smallest branch size to do further splits. Just like a gardener prune real trees of undesired branches, you can prune a decision tree of undesired branches. Most statistical software packages allow you to prune branch splits that do not make enough of a difference to the resulting branches.
I will post an actual example of how to run decision trees in the future. Please subscribe so you don’t miss out.
Speed of execution
Decision Trees is a fast algorithm. A 20 layer deep tree built on 100,000 data points with 40 features took less than a minute!
The theoretical underpinning and arithmetic involved are relatively simple. Decision Trees produce quickly a model that does not require assumptions of statistical property (like assuming the dataset is from a Gaussian/Normal distribution). It does not require sampling of datasets or iterations through feature sets as Random Forest does (I’ll write about Random Forest in future posts).
The tree splitting is done at each branch independently, which is very well suited to parallel computing, utilizing multiple processors/threads, which speeds up the run time significantly as compared to serial processing. Given the amount of data often available for analysis these days, this is empowering.
Because of this speed of execution, I often just build a decision tree with minimal input and then refine the modeling based on the observations from the initial tree built. I may decide further feature engineering is needed (e.g. reformatting existing patient attributes, add other attributes), or that the tree needs fewer levels or branches. I found that this iterative analysis approach efficient.
Clear logic / explanation
The decision tree branches very clearly show the sequence of explanatory variables that it used to arrive at a particular branch or patient cohort. This makes interpreting and explaining the model possible and relatively easy.
The need to understand the predictive model is a key distinction between healthcare predictive analytics and most other industries.
For example, if you want to increase sales through product recommendations for an online retailer, how the algorithm identifies the products a customer will most likely buy next is not as important as the algorithm working really fast and get customers to buy next.
The insights found through healthcare analytics often require medical professionals to implement. The complex nature of medicine, that lives are at stake and the potential for litigation means the logic behind the predictive modeling insights need to be clearly identifiable and understandable.
The clear logic structure of decision trees makes this possible. On the contrary, Neural Net (used in Deep-Learning), does not have a logical structure that allows easy and clear interpretation as does Decision Trees.
Sufficiently accurate (often)
In healthcare, the perfect is the enemy of the good. Yes, sometimes perfect is needed. But if you seek perfection all the time, you will use too much time and effort, missing other opportunities that present greater return on investment.
Decision Trees will make use of all the data available. As such, you can quickly build a model that has a fairly high predictive power. In the extreme case, if you build a tree with as many branches as there are data points, the model will perform perfectly, for that data set. However, the model is overfitting, is overly trained on that specific dataset and will unlikely perform well with new datasets. This is where pruning, using training/validation datasets and a level of judgment becomes important.
For some analyses, knowing the confidence level of a prediction may be important. This is another area where decision trees are weak. The statistical properties at each branch of the tree is not inherently obvious. Yes, you can derive range of prediction at each branch, but you will unlikely get decent statistical measures on your predictions as you can from say a logistic regression.
All that said, I have found that most of the time, Decision Trees generate sufficiently significant insights. Where more nuanced prediction is needed, I use a combination of decision trees and other techniques.
Overall, I would highly recommend a health analyst having Decision Tree algorithm in their arsenal of statistical tools.
I’ll explain the steps to doing predictive modeling in future posts. Please subscribe so you don’t miss out.

4 thoughts on “Decision Trees – intro”